Overview
Welcome to the UvA DL tutorial series on “Training Models at Scale”, in which we explore parallelism strategies for training large deep learning models. The goal of this tutorial is to provide a comprehensive overview of techniques and strategies used for scaling deep learning models, and to provide a hands-on guide to implement these strategies from scratch in JAX with Flax using shard_map. If you are not familiar with JAX yet, we recommend to first check out our Intro to JAX+Flax tutorial.
Why scaling?
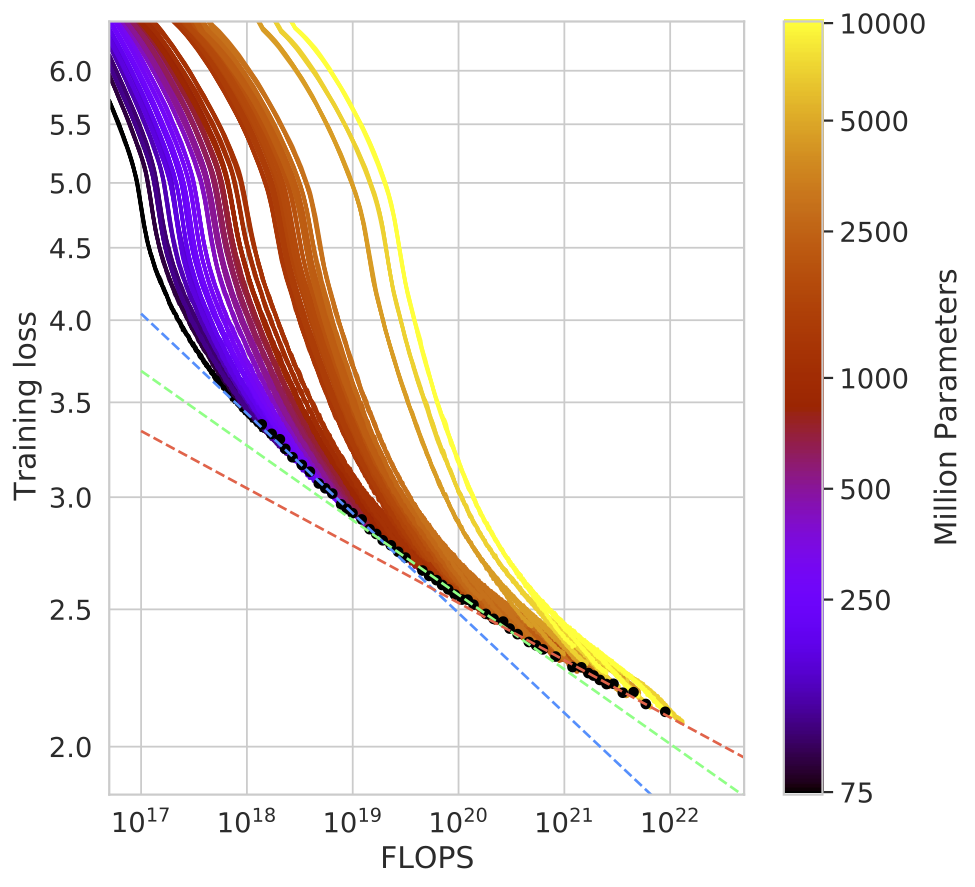
The field of deep learning has seen a rapid increase in model size over the past years, especially with models like GPT-4, Gemini, Llama, Mistral, and Claude. This trend is driven by the observation that larger models often lead to better performance, and the availability of more powerful hardware. For example, the Chincilla paper shows a scaling law for the performance of large language models, which states that the performance of a model scales with the number of parameters. This is illustrated in the figure below, which shows the loss of a model on the y-axis and the number of FLOPs used in training on the x-axis (the parameter count is shown in the legend). The figure shows that the loss decreases as the number of FLOPs and model size increases (figure credit: Hoffman et al., 2022).
Training large models is challenging, and requires careful consideration of the parallelism strategies to efficiently utilize the available hardware. Hence, understanding and implementing parallelism strategies is crucial for training large models. This is the focus of this tutorial series.
What to expect?
While we implement strategies for multi-GPU/-TPU training, the tutorial is designed to be accessible to everyone, regardless of the hardware you have available. All code can be executed on a single CPU, and applied to hardware with multiple GPUs or TPUs without changes. For reference, we provide profiles on a 8-GPU node for most implementations, and discuss the implications of scaling to larger setups.
All parallelization strategies are implemented from scratch in a modular way, so that you can easily reuse the code in your own projects. We provide Python scripts for each part, so that main functions can be reused across notebooks. We also combine all parallelization strategies in a final example, where we train a large model with 3D parallelism.
Generally, we will focus on the key concepts and ideas behind each parallelism strategy, and target with our implementation a one- or multi-node setup with tens or hundreds of GPUs. What we will not cover, since it is out of reach for most of us, is training on thousands of GPUs. In this realm, new challenges arise such as hardware failure, as for example mentioned in the Gemini report. Example resources on this topic are the OPT 175B logbook and Yi Tay’s blog. We will also not cover data loading and preprocessing at scale, which is a topic on its own, and instead test our implementations on artificial data. If you are interested in this topic, you can check out TensorFlow Datasets, PyTorch DataLoader, or Grain.
Finally, the examples shown in these notebooks are focused on educational purposes, and may not always implement all optimizations or efficiency improvements that are possible. We put readability and understandability first, and aim to provide a solid foundation for you to build upon. Potential optimizations and improvements are discussed in the respective parts. If you are interested in code bases that provide highly optimized training setups to work out-of-the-box, you can check out MaxText and t5x (language models in JAX), BigVision and Scenic (vision models in JAX), and DeepSpeed (PyTorch).
Tutorial Structure
The tutorial is structured in 5 parts, each part focusing on a different parallelism strategy. We start with single-GPU optimizations, then move on to data parallelism, pipeline parallelism, tensor parallelism, and finally 3D parallelism. Each part is accompanied by a theoretical introduction, followed by a hands-on coding session. The coding sessions are designed to be self-contained, so that you can easily reuse the code in your own projects. A short overview of the parallelism strategies is given below.

The tutorials are structured as follows:
Single-GPU Optimizations: We start with covering techniques which can already be used for single-GPU trainings, such as mixed precision, gradient accumulation, and gradient checkpointing. We discuss the effect of these techniques on the memory and execution time during training, and show how to profile such models. In the second part, we take the Transformer model as an example and apply these techniques to train a larger model on a single GPU.
Data Parallelism: The second part is dedicated to data parallelism, which is the simplest and most common parallelism strategy used for training large models. We start with an introduction to distributed computing in JAX, and then implement a data parallelism strategy. We then discuss fully-sharded data parallelism (FSDP) and ZeRO optimizer strategies to reduce the memory overhead of data parallelism, and scale to larger models.
Pipeline Parallelism: We next turn to the first of two model parallelism strategies, pipeline parallelism. We start with an introduction to pipeline parallelism and how it distributes the layers of a model over multiple devices. We then implement a pipeline parallelism strategy with microbatching, and discuss the challenge of the pipeline bubble. As one example for mitigating the pipeline bubble, we discuss the concept of looping pipelines, in particular breadth-first pipeline parallelism, and implement it in JAX.
Tensor Parallelism: The fourth part deals with tensor parallelism, which is the second model parallelism strategy and splits the model over its feature dimension. We start with an introduction to tensor parallelism and how it distributes the parameters of a model over multiple devices. We then implement a tensor parallelism strategy, and discuss the challenge of communication-blocking operations. We then discuss the asynchronous linear layers of the 22b Vision Transformer (ViT-22b), and how to implement them in JAX. We use these layers in the third part, where we implement a transformer with tensor parallelism and scale it to a billion parameters. The profiling of the model shows compute-communcation overlap and remaining bottlenecks.
3D Parallelism: The final part combines all parallelism strategies in a final example, where we train a large Transformer model with 3D parallelism. We start with an introduction to 3D parallelism and how it combines data, pipeline, and tensor parallelism. We then implement a 3D parallelism strategy, and discuss the challenges of combining different parallelism strategies. We then profile different configurations of the model, and discuss the implications of scaling to larger setups.
Feedback, Questions or Contributions
We hope you enjoy the tutorial series and learn something new. If you have any questions, feedback, or suggestions, please feel free to reach out to us by creating an issue on the GitHub repository. Similarly, if you find a mistake or a bug, please let us know by creating an issue. We are also happy to accept contributions to the tutorial series, so if you have an addition or want to improve the existing code, feel free to create a pull request.