Tutorial 7: Graph Neural Networks






Note: Interested in JAX? Check out our JAX+Flax version of this tutorial!
In this tutorial, we will discuss the application of neural networks on graphs. Graph Neural Networks (GNNs) have recently gained increasing popularity in both applications and research, including domains such as social networks, knowledge graphs, recommender systems, and bioinformatics. While the theory and math behind GNNs might first seem complicated, the implementation of those models is quite simple and helps in understanding the methodology. Therefore, we will discuss the implementation of basic network layers of a GNN, namely graph convolutions, and attention layers. Finally, we will apply a GNN on a node-level, edge-level, and graph-level tasks.
Below, we will start by importing our standard libraries. We will use PyTorch Lightning as already done in Tutorial 5 and 6.
[1]:
## Standard libraries
import os
import json
import math
import numpy as np
import time
## Imports for plotting
import matplotlib.pyplot as plt
%matplotlib inline
from IPython.display import set_matplotlib_formats
set_matplotlib_formats('svg', 'pdf') # For export
from matplotlib.colors import to_rgb
import matplotlib
matplotlib.rcParams['lines.linewidth'] = 2.0
import seaborn as sns
sns.reset_orig()
sns.set()
## Progress bar
from tqdm.notebook import tqdm
## PyTorch
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.data as data
import torch.optim as optim
# Torchvision
import torchvision
from torchvision.datasets import CIFAR10
from torchvision import transforms
# PyTorch Lightning
try:
import pytorch_lightning as pl
except ModuleNotFoundError: # Google Colab does not have PyTorch Lightning installed by default. Hence, we do it here if necessary
!pip install --quiet pytorch-lightning>=1.4
import pytorch_lightning as pl
from pytorch_lightning.callbacks import LearningRateMonitor, ModelCheckpoint
# Path to the folder where the datasets are/should be downloaded (e.g. CIFAR10)
DATASET_PATH = "../data"
# Path to the folder where the pretrained models are saved
CHECKPOINT_PATH = "../saved_models/tutorial7"
# Setting the seed
pl.seed_everything(42)
# Ensure that all operations are deterministic on GPU (if used) for reproducibility
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
device = torch.device("cuda:0") if torch.cuda.is_available() else torch.device("cpu")
print(device)
cuda:0
We also have a few pre-trained models we download below.
[2]:
import urllib.request
from urllib.error import HTTPError
# Github URL where saved models are stored for this tutorial
base_url = "https://raw.githubusercontent.com/phlippe/saved_models/main/tutorial7/"
# Files to download
pretrained_files = ["NodeLevelMLP.ckpt", "NodeLevelGNN.ckpt", "GraphLevelGraphConv.ckpt"]
# Create checkpoint path if it doesn't exist yet
os.makedirs(CHECKPOINT_PATH, exist_ok=True)
# For each file, check whether it already exists. If not, try downloading it.
for file_name in pretrained_files:
file_path = os.path.join(CHECKPOINT_PATH, file_name)
if "/" in file_name:
os.makedirs(file_path.rsplit("/",1)[0], exist_ok=True)
if not os.path.isfile(file_path):
file_url = base_url + file_name
print(f"Downloading {file_url}...")
try:
urllib.request.urlretrieve(file_url, file_path)
except HTTPError as e:
print("Something went wrong. Please try to download the file from the GDrive folder, or contact the author with the full output including the following error:\n", e)
Graph Neural Networks
Graph representation
Before starting the discussion of specific neural network operations on graphs, we should consider how to represent a graph. Mathematically, a graph \(\mathcal{G}\) is defined as a tuple of a set of nodes/vertices \(V\), and a set of edges/links \(E\): \(\mathcal{G}=(V,E)\). Each edge is a pair of two vertices, and represents a connection between them. For instance, let’s look at the following graph:

The vertices are \(V=\{1,2,3,4\}\), and edges \(E=\{(1,2), (2,3), (2,4), (3,4)\}\). Note that for simplicity, we assume the graph to be undirected and hence don’t add mirrored pairs like \((2,1)\). In application, vertices and edge can often have specific attributes, and edges can even be directed. The question is how we could represent this diversity in an efficient way for matrix operations. Usually, for the edges, we decide between two variants: an adjacency matrix, or a list of paired vertex indices.
The adjacency matrix \(A\) is a square matrix whose elements indicate whether pairs of vertices are adjacent, i.e. connected, or not. In the simplest case, \(A_{ij}\) is 1 if there is a connection from node \(i\) to \(j\), and otherwise 0. If we have edge attributes or different categories of edges in a graph, this information can be added to the matrix as well. For an undirected graph, keep in mind that \(A\) is a symmetric matrix (\(A_{ij}=A_{ji}\)). For the example graph above, we have the following adjacency matrix:
While expressing a graph as a list of edges is more efficient in terms of memory and (possibly) computation, using an adjacency matrix is more intuitive and simpler to implement. In our implementations below, we will rely on the adjacency matrix to keep the code simple. However, common libraries use edge lists, which we will discuss later more. Alternatively, we could also use the list of edges to define a sparse adjacency matrix with which we can work as if it was a dense matrix, but allows
more memory-efficient operations. PyTorch supports this with the sub-package torch.sparse (documentation) which is however still in a beta-stage (API might change in future).
Graph Convolutions
Graph Convolutional Networks have been introduced by Kipf et al. in 2016 at the University of Amsterdam. He also wrote a great blog post about this topic, which is recommended if you want to read about GCNs from a different perspective. GCNs are similar to convolutions in images in the sense that the “filter” parameters are typically shared over all locations in the graph. At the same time, GCNs rely on message passing methods, which means that vertices exchange information with the neighbors, and send “messages” to each other. Before looking at the math, we can try to visually understand how GCNs work. The first step is that each node creates a feature vector that represents the message it wants to send to all its neighbors. In the second step, the messages are sent to the neighbors, so that a node receives one message per adjacent node. Below we have visualized the two steps for our example graph.

If we want to formulate that in more mathematical terms, we need to first decide how to combine all the messages a node receives. As the number of messages vary across nodes, we need an operation that works for any number. Hence, the usual way to go is to sum or take the mean. Given the previous features of nodes \(H^{(l)}\), the GCN layer is defined as follows:
\(W^{(l)}\) is the weight parameters with which we transform the input features into messages (\(H^{(l)}W^{(l)}\)). To the adjacency matrix \(A\) we add the identity matrix so that each node sends its own message also to itself: \(\hat{A}=A+I\). Finally, to take the average instead of summing, we calculate the matrix \(\hat{D}\) which is a diagonal matrix with \(D_{ii}\) denoting the number of neighbors node \(i\) has. \(\sigma\) represents an arbitrary activation function, and not necessarily the sigmoid (usually a ReLU-based activation function is used in GNNs).
When implementing the GCN layer in PyTorch, we can take advantage of the flexible operations on tensors. Instead of defining a matrix \(\hat{D}\), we can simply divide the summed messages by the number of neighbors afterward. Additionally, we replace the weight matrix with a linear layer, which additionally allows us to add a bias. Written as a PyTorch module, the GCN layer is defined as follows:
[3]:
class GCNLayer(nn.Module):
def __init__(self, c_in, c_out):
super().__init__()
self.projection = nn.Linear(c_in, c_out)
def forward(self, node_feats, adj_matrix):
"""
Inputs:
node_feats - Tensor with node features of shape [batch_size, num_nodes, c_in]
adj_matrix - Batch of adjacency matrices of the graph. If there is an edge from i to j, adj_matrix[b,i,j]=1 else 0.
Supports directed edges by non-symmetric matrices. Assumes to already have added the identity connections.
Shape: [batch_size, num_nodes, num_nodes]
"""
# Num neighbours = number of incoming edges
num_neighbours = adj_matrix.sum(dim=-1, keepdims=True)
node_feats = self.projection(node_feats)
node_feats = torch.bmm(adj_matrix, node_feats)
node_feats = node_feats / num_neighbours
return node_feats
To further understand the GCN layer, we can apply it to our example graph above. First, let’s specify some node features and the adjacency matrix with added self-connections:
[4]:
node_feats = torch.arange(8, dtype=torch.float32).view(1, 4, 2)
adj_matrix = torch.Tensor([[[1, 1, 0, 0],
[1, 1, 1, 1],
[0, 1, 1, 1],
[0, 1, 1, 1]]])
print("Node features:\n", node_feats)
print("\nAdjacency matrix:\n", adj_matrix)
Node features:
tensor([[[0., 1.],
[2., 3.],
[4., 5.],
[6., 7.]]])
Adjacency matrix:
tensor([[[1., 1., 0., 0.],
[1., 1., 1., 1.],
[0., 1., 1., 1.],
[0., 1., 1., 1.]]])
Next, let’s apply a GCN layer to it. For simplicity, we initialize the linear weight matrix as an identity matrix so that the input features are equal to the messages. This makes it easier for us to verify the message passing operation.
[5]:
layer = GCNLayer(c_in=2, c_out=2)
layer.projection.weight.data = torch.Tensor([[1., 0.], [0., 1.]])
layer.projection.bias.data = torch.Tensor([0., 0.])
with torch.no_grad():
out_feats = layer(node_feats, adj_matrix)
print("Adjacency matrix", adj_matrix)
print("Input features", node_feats)
print("Output features", out_feats)
Adjacency matrix tensor([[[1., 1., 0., 0.],
[1., 1., 1., 1.],
[0., 1., 1., 1.],
[0., 1., 1., 1.]]])
Input features tensor([[[0., 1.],
[2., 3.],
[4., 5.],
[6., 7.]]])
Output features tensor([[[1., 2.],
[3., 4.],
[4., 5.],
[4., 5.]]])
As we can see, the first node’s output values are the average of itself and the second node. Similarly, we can verify all other nodes. However, in a GNN, we would also want to allow feature exchange between nodes beyond its neighbors. This can be achieved by applying multiple GCN layers, which gives us the final layout of a GNN. The GNN can be build up by a sequence of GCN layers and non-linearities such as ReLU. For a visualization, see below (figure credit - Thomas Kipf, 2016).
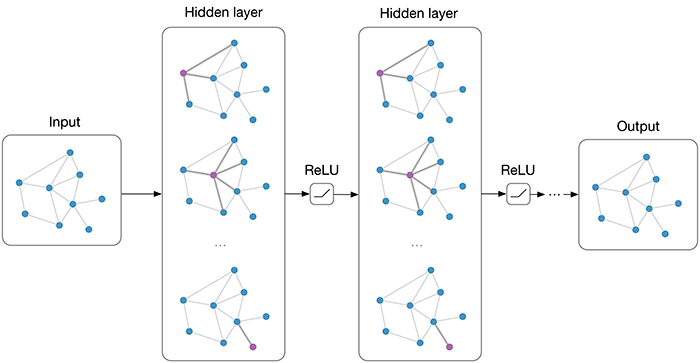
However, one issue we can see from looking at the example above is that the output features for nodes 3 and 4 are the same because they have the same adjacent nodes (including itself). Therefore, GCN layers can make the network forget node-specific information if we just take a mean over all messages. Multiple possible improvements have been proposed. While the simplest option might be using residual connections, the more common approach is to either weigh the self-connections higher or define a separate weight matrix for the self-connections. Alternatively, we can re-visit a concept from the last tutorial: attention.
Graph Attention
If you remember from the last tutorial, attention describes a weighted average of multiple elements with the weights dynamically computed based on an input query and elements’ keys (if you haven’t read Tutorial 6 yet, it is recommended to at least go through the very first section called What is Attention?). This concept can be similarly applied to graphs, one of such is the Graph Attention Network (called GAT, proposed by Velickovic et al., 2017). Similarly to the GCN, the graph attention layer creates a message for each node using a linear layer/weight matrix. For the attention part, it uses the message from the node itself as a query, and the messages to average as both keys and values (note that this also includes the message to itself). The score function \(f_{attn}\) is implemented as a one-layer MLP which maps the query and key to a single value. The MLP looks as follows (figure credit - Velickovic et al.):

\(h_i\) and \(h_j\) are the original features from node \(i\) and \(j\) respectively, and represent the messages of the layer with \(\mathbf{W}\) as weight matrix. \(\mathbf{a}\) is the weight matrix of the MLP, which has the shape \([1,2\times d_{\text{message}}]\), and \(\alpha_{ij}\) the final attention weight from node \(i\) to \(j\). The calculation can be described as follows:
The operator \(||\) represents the concatenation, and \(\mathcal{N}_i\) the indices of the neighbors of node \(i\). Note that in contrast to usual practice, we apply a non-linearity (here LeakyReLU) before the softmax over elements. Although it seems like a minor change at first, it is crucial for the attention to depend on the original input. Specifically, let’s remove the non-linearity for a second, and try to simplify the expression:
We can see that without the non-linearity, the attention term with \(h_i\) actually cancels itself out, resulting in the attention being independent of the node itself. Hence, we would have the same issue as the GCN of creating the same output features for nodes with the same neighbors. This is why the LeakyReLU is crucial and adds some dependency on \(h_i\) to the attention.
Once we obtain all attention factors, we can calculate the output features for each node by performing the weighted average:
\(\sigma\) is yet another non-linearity, as in the GCN layer. Visually, we can represent the full message passing in an attention layer as follows (figure credit - Velickovic et al.):
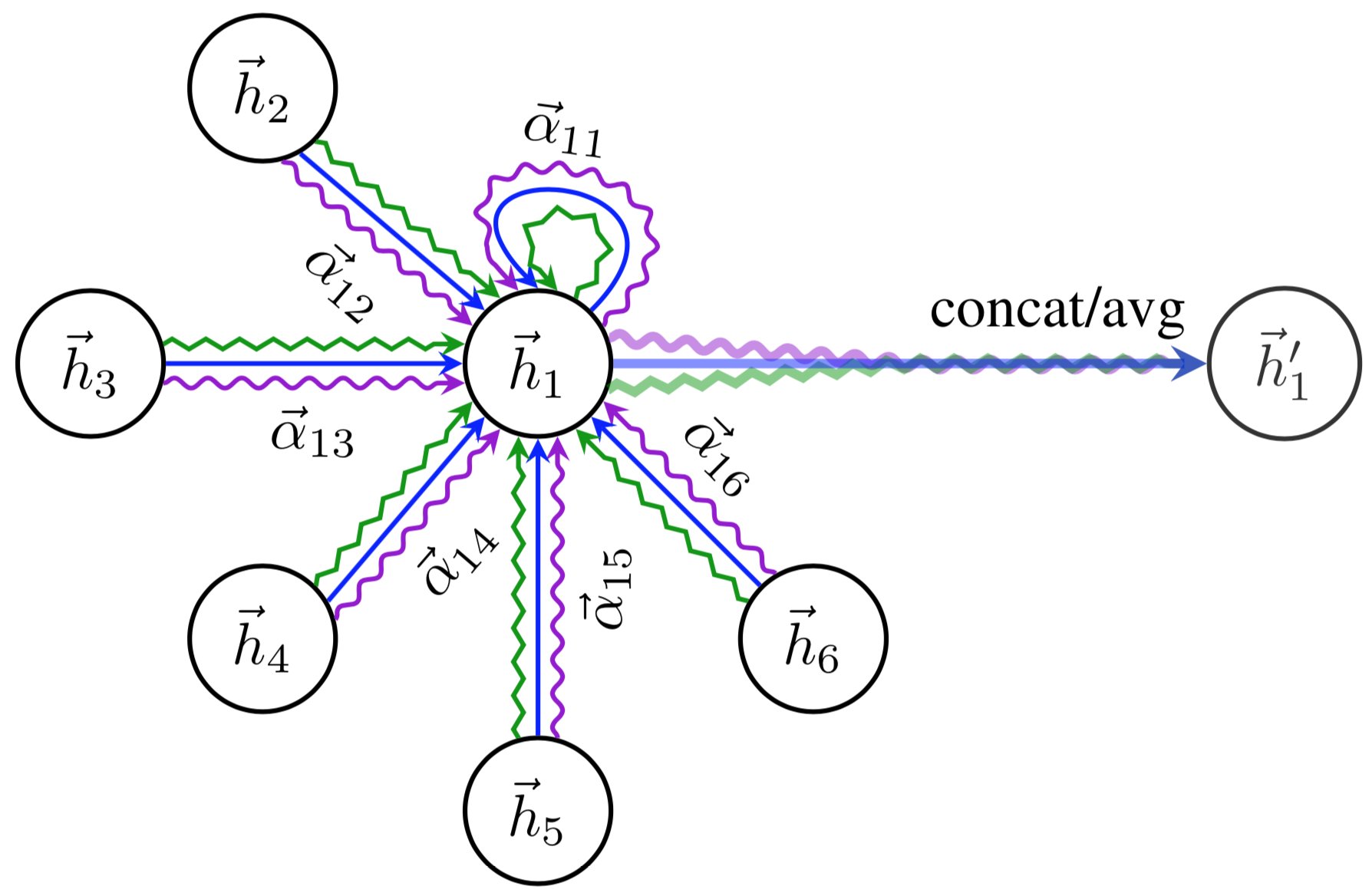
To increase the expressiveness of the graph attention network, Velickovic et al. proposed to extend it to multiple heads similar to the Multi-Head Attention block in Transformers. This results in \(N\) attention layers being applied in parallel. In the image above, it is visualized as three different colors of arrows (green, blue, and purple) that are afterward concatenated. The average is only applied for the very final prediction layer in a network.
After having discussed the graph attention layer in detail, we can implement it below:
[6]:
class GATLayer(nn.Module):
def __init__(self, c_in, c_out, num_heads=1, concat_heads=True, alpha=0.2):
"""
Inputs:
c_in - Dimensionality of input features
c_out - Dimensionality of output features
num_heads - Number of heads, i.e. attention mechanisms to apply in parallel. The
output features are equally split up over the heads if concat_heads=True.
concat_heads - If True, the output of the different heads is concatenated instead of averaged.
alpha - Negative slope of the LeakyReLU activation.
"""
super().__init__()
self.num_heads = num_heads
self.concat_heads = concat_heads
if self.concat_heads:
assert c_out % num_heads == 0, "Number of output features must be a multiple of the count of heads."
c_out = c_out // num_heads
# Sub-modules and parameters needed in the layer
self.projection = nn.Linear(c_in, c_out * num_heads)
self.a = nn.Parameter(torch.Tensor(num_heads, 2 * c_out)) # One per head
self.leakyrelu = nn.LeakyReLU(alpha)
# Initialization from the original implementation
nn.init.xavier_uniform_(self.projection.weight.data, gain=1.414)
nn.init.xavier_uniform_(self.a.data, gain=1.414)
def forward(self, node_feats, adj_matrix, print_attn_probs=False):
"""
Inputs:
node_feats - Input features of the node. Shape: [batch_size, c_in]
adj_matrix - Adjacency matrix including self-connections. Shape: [batch_size, num_nodes, num_nodes]
print_attn_probs - If True, the attention weights are printed during the forward pass (for debugging purposes)
"""
batch_size, num_nodes = node_feats.size(0), node_feats.size(1)
# Apply linear layer and sort nodes by head
node_feats = self.projection(node_feats)
node_feats = node_feats.view(batch_size, num_nodes, self.num_heads, -1)
# We need to calculate the attention logits for every edge in the adjacency matrix
# Doing this on all possible combinations of nodes is very expensive
# => Create a tensor of [W*h_i||W*h_j] with i and j being the indices of all edges
edges = adj_matrix.nonzero(as_tuple=False) # Returns indices where the adjacency matrix is not 0 => edges
node_feats_flat = node_feats.view(batch_size * num_nodes, self.num_heads, -1)
edge_indices_row = edges[:,0] * num_nodes + edges[:,1]
edge_indices_col = edges[:,0] * num_nodes + edges[:,2]
a_input = torch.cat([
torch.index_select(input=node_feats_flat, index=edge_indices_row, dim=0),
torch.index_select(input=node_feats_flat, index=edge_indices_col, dim=0)
], dim=-1) # Index select returns a tensor with node_feats_flat being indexed at the desired positions along dim=0
# Calculate attention MLP output (independent for each head)
attn_logits = torch.einsum('bhc,hc->bh', a_input, self.a)
attn_logits = self.leakyrelu(attn_logits)
# Map list of attention values back into a matrix
attn_matrix = attn_logits.new_zeros(adj_matrix.shape+(self.num_heads,)).fill_(-9e15)
attn_matrix[adj_matrix[...,None].repeat(1,1,1,self.num_heads) == 1] = attn_logits.reshape(-1)
# Weighted average of attention
attn_probs = F.softmax(attn_matrix, dim=2)
if print_attn_probs:
print("Attention probs\n", attn_probs.permute(0, 3, 1, 2))
node_feats = torch.einsum('bijh,bjhc->bihc', attn_probs, node_feats)
# If heads should be concatenated, we can do this by reshaping. Otherwise, take mean
if self.concat_heads:
node_feats = node_feats.reshape(batch_size, num_nodes, -1)
else:
node_feats = node_feats.mean(dim=2)
return node_feats
Again, we can apply the graph attention layer on our example graph above to understand the dynamics better. As before, the input layer is initialized as an identity matrix, but we set \(\mathbf{a}\) to be a vector of arbitrary numbers to obtain different attention values. We use two heads to show the parallel, independent attention mechanisms working in the layer.
[7]:
layer = GATLayer(2, 2, num_heads=2)
layer.projection.weight.data = torch.Tensor([[1., 0.], [0., 1.]])
layer.projection.bias.data = torch.Tensor([0., 0.])
layer.a.data = torch.Tensor([[-0.2, 0.3], [0.1, -0.1]])
with torch.no_grad():
out_feats = layer(node_feats, adj_matrix, print_attn_probs=True)
print("Adjacency matrix", adj_matrix)
print("Input features", node_feats)
print("Output features", out_feats)
Attention probs
tensor([[[[0.3543, 0.6457, 0.0000, 0.0000],
[0.1096, 0.1450, 0.2642, 0.4813],
[0.0000, 0.1858, 0.2885, 0.5257],
[0.0000, 0.2391, 0.2696, 0.4913]],
[[0.5100, 0.4900, 0.0000, 0.0000],
[0.2975, 0.2436, 0.2340, 0.2249],
[0.0000, 0.3838, 0.3142, 0.3019],
[0.0000, 0.4018, 0.3289, 0.2693]]]])
Adjacency matrix tensor([[[1., 1., 0., 0.],
[1., 1., 1., 1.],
[0., 1., 1., 1.],
[0., 1., 1., 1.]]])
Input features tensor([[[0., 1.],
[2., 3.],
[4., 5.],
[6., 7.]]])
Output features tensor([[[1.2913, 1.9800],
[4.2344, 3.7725],
[4.6798, 4.8362],
[4.5043, 4.7351]]])
We recommend that you try to calculate the attention matrix at least for one head and one node for yourself. The entries are 0 where there does not exist an edge between \(i\) and \(j\). For the others, we see a diverse set of attention probabilities. Moreover, the output features of node 3 and 4 are now different although they have the same neighbors.
PyTorch Geometric
We had mentioned before that implementing graph networks with adjacency matrix is simple and straight-forward but can be computationally expensive for large graphs. Many real-world graphs can reach over 200k nodes, for which adjacency matrix-based implementations fail. There are a lot of optimizations possible when implementing GNNs, and luckily, there exist packages that provide such layers. The most popular packages for PyTorch are PyTorch
Geometric and the Deep Graph Library (the latter being actually framework agnostic). Which one to use depends on the project you are planning to do and personal taste. In this tutorial, we will look at PyTorch Geometric as part of the PyTorch family. Similar to PyTorch Lightning, PyTorch Geometric is not installed by default on GoogleColab (and actually also not in our dl2021 environment due to many
dependencies that would be unnecessary for the practicals). Hence, let’s import and/or install it below:
[8]:
# torch geometric
try:
import torch_geometric
except ModuleNotFoundError:
# Installing torch geometric packages with specific CUDA+PyTorch version.
# See https://pytorch-geometric.readthedocs.io/en/latest/notes/installation.html for details
TORCH = torch.__version__.split('+')[0]
CUDA = 'cu' + torch.version.cuda.replace('.','')
!pip install torch-scatter -f https://pytorch-geometric.com/whl/torch-{TORCH}+{CUDA}.html
!pip install torch-sparse -f https://pytorch-geometric.com/whl/torch-{TORCH}+{CUDA}.html
!pip install torch-cluster -f https://pytorch-geometric.com/whl/torch-{TORCH}+{CUDA}.html
!pip install torch-spline-conv -f https://pytorch-geometric.com/whl/torch-{TORCH}+{CUDA}.html
!pip install torch-geometric
import torch_geometric
import torch_geometric.nn as geom_nn
import torch_geometric.data as geom_data
RDKit WARNING: [19:12:50] Enabling RDKit 2019.09.3 jupyter extensions
PyTorch Geometric provides us a set of common graph layers, including the GCN and GAT layer we implemented above. Additionally, similar to PyTorch’s torchvision, it provides the common graph datasets and transformations on those to simplify training. Compared to our implementation above, PyTorch Geometric uses a list of index pairs to represent the edges. The details of this library will be explored further in our experiments.
In our tasks below, we want to allow us to pick from a multitude of graph layers. Thus, we define again below a dictionary to access those using a string:
[9]:
gnn_layer_by_name = {
"GCN": geom_nn.GCNConv,
"GAT": geom_nn.GATConv,
"GraphConv": geom_nn.GraphConv
}
Additionally to GCN and GAT, we added the layer geom_nn.GraphConv (documentation). GraphConv is a GCN with a separate weight matrix for the self-connections. Mathematically, this would be:
In this formula, the neighbor’s messages are added instead of averaged. However, PyTorch Geometric provides the argument aggr to switch between summing, averaging, and max pooling.
Experiments on graph structures
Tasks on graph-structured data can be grouped into three groups: node-level, edge-level and graph-level. The different levels describe on which level we want to perform classification/regression. We will discuss all three types in more detail below.
Node-level tasks: Semi-supervised node classification
Node-level tasks have the goal to classify nodes in a graph. Usually, we have given a single, large graph with >1000 nodes of which a certain amount of nodes are labeled. We learn to classify those labeled examples during training and try to generalize to the unlabeled nodes.
A popular example that we will use in this tutorial is the Cora dataset, a citation network among papers. The Cora consists of 2708 scientific publications with links between each other representing the citation of one paper by another. The task is to classify each publication into one of seven classes. Each publication is represented by a bag-of-words vector. This means that we have a vector of 1433 elements for each publication, where a 1 at feature \(i\) indicates that the \(i\)-th word of a pre-defined dictionary is in the article. Binary bag-of-words representations are commonly used when we need very simple encodings, and already have an intuition of what words to expect in a network. There exist much better approaches, but we will leave this to the NLP courses to discuss.
We will load the dataset below:
[10]:
cora_dataset = torch_geometric.datasets.Planetoid(root=DATASET_PATH, name="Cora")
Let’s look at how PyTorch Geometric represents the graph data. Note that although we have a single graph, PyTorch Geometric returns a dataset for compatibility to other datasets.
[11]:
cora_dataset[0]
[11]:
Data(edge_index=[2, 10556], test_mask=[2708], train_mask=[2708], val_mask=[2708], x=[2708, 1433], y=[2708])
The graph is represented by a Data object (documentation) which we can access as a standard Python namespace. The edge index tensor is the list of edges in the graph and contains the mirrored version of each edge for undirected graphs. The train_mask, val_mask, and test_mask are boolean masks that indicate which nodes we should use for training, validation, and testing. The x
tensor is the feature tensor of our 2708 publications, and y the labels for all nodes.
After having seen the data, we can implement a simple graph neural network. The GNN applies a sequence of graph layers (GCN, GAT, or GraphConv), ReLU as activation function, and dropout for regularization. See below for the specific implementation.
[12]:
class GNNModel(nn.Module):
def __init__(self, c_in, c_hidden, c_out, num_layers=2, layer_name="GCN", dp_rate=0.1, **kwargs):
"""
Inputs:
c_in - Dimension of input features
c_hidden - Dimension of hidden features
c_out - Dimension of the output features. Usually number of classes in classification
num_layers - Number of "hidden" graph layers
layer_name - String of the graph layer to use
dp_rate - Dropout rate to apply throughout the network
kwargs - Additional arguments for the graph layer (e.g. number of heads for GAT)
"""
super().__init__()
gnn_layer = gnn_layer_by_name[layer_name]
layers = []
in_channels, out_channels = c_in, c_hidden
for l_idx in range(num_layers-1):
layers += [
gnn_layer(in_channels=in_channels,
out_channels=out_channels,
**kwargs),
nn.ReLU(inplace=True),
nn.Dropout(dp_rate)
]
in_channels = c_hidden
layers += [gnn_layer(in_channels=in_channels,
out_channels=c_out,
**kwargs)]
self.layers = nn.ModuleList(layers)
def forward(self, x, edge_index):
"""
Inputs:
x - Input features per node
edge_index - List of vertex index pairs representing the edges in the graph (PyTorch geometric notation)
"""
for l in self.layers:
# For graph layers, we need to add the "edge_index" tensor as additional input
# All PyTorch Geometric graph layer inherit the class "MessagePassing", hence
# we can simply check the class type.
if isinstance(l, geom_nn.MessagePassing):
x = l(x, edge_index)
else:
x = l(x)
return x
Good practice in node-level tasks is to create an MLP baseline that is applied to each node independently. This way we can verify whether adding the graph information to the model indeed improves the prediction, or not. It might also be that the features per node are already expressive enough to clearly point towards a specific class. To check this, we implement a simple MLP below.
[13]:
class MLPModel(nn.Module):
def __init__(self, c_in, c_hidden, c_out, num_layers=2, dp_rate=0.1):
"""
Inputs:
c_in - Dimension of input features
c_hidden - Dimension of hidden features
c_out - Dimension of the output features. Usually number of classes in classification
num_layers - Number of hidden layers
dp_rate - Dropout rate to apply throughout the network
"""
super().__init__()
layers = []
in_channels, out_channels = c_in, c_hidden
for l_idx in range(num_layers-1):
layers += [
nn.Linear(in_channels, out_channels),
nn.ReLU(inplace=True),
nn.Dropout(dp_rate)
]
in_channels = c_hidden
layers += [nn.Linear(in_channels, c_out)]
self.layers = nn.Sequential(*layers)
def forward(self, x, *args, **kwargs):
"""
Inputs:
x - Input features per node
"""
return self.layers(x)
Finally, we can merge the models into a PyTorch Lightning module which handles the training, validation, and testing for us.
[14]:
class NodeLevelGNN(pl.LightningModule):
def __init__(self, model_name, **model_kwargs):
super().__init__()
# Saving hyperparameters
self.save_hyperparameters()
if model_name == "MLP":
self.model = MLPModel(**model_kwargs)
else:
self.model = GNNModel(**model_kwargs)
self.loss_module = nn.CrossEntropyLoss()
def forward(self, data, mode="train"):
x, edge_index = data.x, data.edge_index
x = self.model(x, edge_index)
# Only calculate the loss on the nodes corresponding to the mask
if mode == "train":
mask = data.train_mask
elif mode == "val":
mask = data.val_mask
elif mode == "test":
mask = data.test_mask
else:
assert False, f"Unknown forward mode: {mode}"
loss = self.loss_module(x[mask], data.y[mask])
acc = (x[mask].argmax(dim=-1) == data.y[mask]).sum().float() / mask.sum()
return loss, acc
def configure_optimizers(self):
# We use SGD here, but Adam works as well
optimizer = optim.SGD(self.parameters(), lr=0.1, momentum=0.9, weight_decay=2e-3)
return optimizer
def training_step(self, batch, batch_idx):
loss, acc = self.forward(batch, mode="train")
self.log('train_loss', loss)
self.log('train_acc', acc)
return loss
def validation_step(self, batch, batch_idx):
_, acc = self.forward(batch, mode="val")
self.log('val_acc', acc)
def test_step(self, batch, batch_idx):
_, acc = self.forward(batch, mode="test")
self.log('test_acc', acc)
Additionally to the Lightning module, we define a training function below. As we have a single graph, we use a batch size of 1 for the data loader and share the same data loader for the train, validation, and test set (the mask is picked inside the Lightning module). Besides, we set the argument enable_progress_bar to False as it usually shows the progress per epoch, but an epoch only consists of a single step. The rest of the code is very similar to what we have seen in Tutorial 5 and 6
already.
[15]:
def train_node_classifier(model_name, dataset, **model_kwargs):
pl.seed_everything(42)
node_data_loader = geom_data.DataLoader(dataset, batch_size=1)
# Create a PyTorch Lightning trainer with the generation callback
root_dir = os.path.join(CHECKPOINT_PATH, "NodeLevel" + model_name)
os.makedirs(root_dir, exist_ok=True)
trainer = pl.Trainer(default_root_dir=root_dir,
callbacks=[ModelCheckpoint(save_weights_only=True, mode="max", monitor="val_acc")],
accelerator="gpu" if str(device).startswith("cuda") else "cpu",
devices=1,
max_epochs=200,
enable_progress_bar=False) # False because epoch size is 1
trainer.logger._default_hp_metric = None # Optional logging argument that we don't need
# Check whether pretrained model exists. If yes, load it and skip training
pretrained_filename = os.path.join(CHECKPOINT_PATH, f"NodeLevel{model_name}.ckpt")
if os.path.isfile(pretrained_filename):
print("Found pretrained model, loading...")
model = NodeLevelGNN.load_from_checkpoint(pretrained_filename)
else:
pl.seed_everything()
model = NodeLevelGNN(model_name=model_name, c_in=dataset.num_node_features, c_out=dataset.num_classes, **model_kwargs)
trainer.fit(model, node_data_loader, node_data_loader)
model = NodeLevelGNN.load_from_checkpoint(trainer.checkpoint_callback.best_model_path)
# Test best model on the test set
test_result = trainer.test(model, node_data_loader, verbose=False)
batch = next(iter(node_data_loader))
batch = batch.to(model.device)
_, train_acc = model.forward(batch, mode="train")
_, val_acc = model.forward(batch, mode="val")
result = {"train": train_acc,
"val": val_acc,
"test": test_result[0]['test_acc']}
return model, result
Finally, we can train our models. First, let’s train the simple MLP:
[16]:
# Small function for printing the test scores
def print_results(result_dict):
if "train" in result_dict:
print(f"Train accuracy: {(100.0*result_dict['train']):4.2f}%")
if "val" in result_dict:
print(f"Val accuracy: {(100.0*result_dict['val']):4.2f}%")
print(f"Test accuracy: {(100.0*result_dict['test']):4.2f}%")
[17]:
node_mlp_model, node_mlp_result = train_node_classifier(model_name="MLP",
dataset=cora_dataset,
c_hidden=16,
num_layers=2,
dp_rate=0.1)
print_results(node_mlp_result)
GPU available: True, used: True
WARNING: Logging before flag parsing goes to stderr.
I1113 19:12:52.401648 139969460983616 distributed.py:49] GPU available: True, used: True
TPU available: False, using: 0 TPU cores
I1113 19:12:52.403518 139969460983616 distributed.py:49] TPU available: False, using: 0 TPU cores
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
I1113 19:12:52.404974 139969460983616 accelerator_connector.py:385] LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
Found pretrained model, loading...
Train accuracy: 96.43%
Val accuracy: 52.60%
Test accuracy: 60.60%
/home/phillip/anaconda3/envs/nlp1/lib/python3.7/site-packages/pytorch_lightning/utilities/distributed.py:45: UserWarning: The dataloader, test dataloader 0, does not have many workers which may be a bottleneck. Consider increasing the value of the `num_workers` argument` (try 16 which is the number of cpus on this machine) in the `DataLoader` init to improve performance.
warnings.warn(*args, **kwargs)
Although the MLP can overfit on the training dataset because of the high-dimensional input features, it does not perform too well on the test set. Let’s see if we can beat this score with our graph networks:
[18]:
node_gnn_model, node_gnn_result = train_node_classifier(model_name="GNN",
layer_name="GCN",
dataset=cora_dataset,
c_hidden=16,
num_layers=2,
dp_rate=0.1)
print_results(node_gnn_result)
GPU available: True, used: True
I1113 19:12:53.906714 139969460983616 distributed.py:49] GPU available: True, used: True
TPU available: False, using: 0 TPU cores
I1113 19:12:53.907762 139969460983616 distributed.py:49] TPU available: False, using: 0 TPU cores
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
I1113 19:12:53.909639 139969460983616 accelerator_connector.py:385] LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
Found pretrained model, loading...
Train accuracy: 100.00%
Val accuracy: 77.20%
Test accuracy: 82.40%
As we would have hoped for, the GNN model outperforms the MLP by quite a margin. This shows that using the graph information indeed improves our predictions and lets us generalizes better.
The hyperparameters in the model have been chosen to create a relatively small network. This is because the first layer with an input dimension of 1433 can be relatively expensive to perform for large graphs. In general, GNNs can become relatively expensive for very big graphs. This is why such GNNs either have a small hidden size or use a special batching strategy where we sample a connected subgraph of the big, original graph.
Edge-level tasks: Link prediction
In some applications, we might have to predict on an edge-level instead of node-level. The most common edge-level task in GNN is link prediction. Link prediction means that given a graph, we want to predict whether there will be/should be an edge between two nodes or not. For example, in a social network, this is used by Facebook and co to propose new friends to you. Again, graph level information can be crucial to perform this task. The output prediction is usually done by performing a similarity metric on the pair of node features, which should be 1 if there should be a link, and otherwise close to 0. To keep the tutorial short, we will not implement this task ourselves. Nevertheless, there are many good resources out there if you are interested in looking closer at this task. Tutorials and papers for this topic include:
Graph Neural Networks: A Review of Methods and Applications, Zhou et al. 2019
Link Prediction Based on Graph Neural Networks, Zhang and Chen, 2018.
Graph-level tasks: Graph classification
Finally, in this part of the tutorial, we will have a closer look at how to apply GNNs to the task of graph classification. The goal is to classify an entire graph instead of single nodes or edges. Therefore, we are also given a dataset of multiple graphs that we need to classify based on some structural graph properties. The most common task for graph classification is molecular property prediction, in which molecules are represented as graphs. Each atom is linked to a node, and edges in the graph are the bonds between atoms. For example, look at the figure below.

On the left, we have an arbitrary, small molecule with different atoms, whereas the right part of the image shows the graph representation. The atom types are abstracted as node features (e.g. a one-hot vector), and the different bond types are used as edge features. For simplicity, we will neglect the edge attributes in this tutorial, but you can include by using methods like the Relational Graph Convolution that uses a different weight matrix for each edge type.
The dataset we will use below is called the MUTAG dataset. It is a common small benchmark for graph classification algorithms, and contain 188 graphs with 18 nodes and 20 edges on average for each graph. The graph nodes have 7 different labels/atom types, and the binary graph labels represent “their mutagenic effect on a specific gram negative bacterium” (the specific meaning of the labels are not too important here). The dataset is part of a large collection of different graph classification
datasets, known as the TUDatasets, which is directly accessible via torch_geometric.datasets.TUDataset (documentation) in PyTorch Geometric. We can load the dataset below.
[19]:
tu_dataset = torch_geometric.datasets.TUDataset(root=DATASET_PATH, name="MUTAG")
Let’s look at some statistics for the dataset:
[20]:
print("Data object:", tu_dataset.data)
print("Length:", len(tu_dataset))
print(f"Average label: {tu_dataset.data.y.float().mean().item():4.2f}")
Data object: Data(edge_attr=[7442, 4], edge_index=[2, 7442], x=[3371, 7], y=[188])
Length: 188
Average label: 0.66
The first line shows how the dataset stores different graphs. The nodes, edges, and labels of each graph are concatenated to one tensor, and the dataset stores the indices where to split the tensors correspondingly. The length of the dataset is the number of graphs we have, and the “average label” denotes the percentage of the graph with label 1. As long as the percentage is in the range of 0.5, we have a relatively balanced dataset. It happens quite often that graph datasets are very imbalanced, hence checking the class balance is always a good thing to do.
Next, we will split our dataset into a training and test part. Note that we do not use a validation set this time because of the small size of the dataset. Therefore, our model might overfit slightly on the validation set due to the noise of the evaluation, but we still get an estimate of the performance on untrained data.
[21]:
torch.manual_seed(42)
tu_dataset.shuffle()
train_dataset = tu_dataset[:150]
test_dataset = tu_dataset[150:]
When using a data loader, we encounter a problem with batching \(N\) graphs. Each graph in the batch can have a different number of nodes and edges, and hence we would require a lot of padding to obtain a single tensor. Torch geometric uses a different, more efficient approach: we can view the \(N\) graphs in a batch as a single large graph with concatenated node and edge list. As there is no edge between the \(N\) graphs, running GNN layers on the large graph gives us the same output as running the GNN on each graph separately. Visually, this batching strategy is visualized below (figure credit - PyTorch Geometric team, tutorial here).
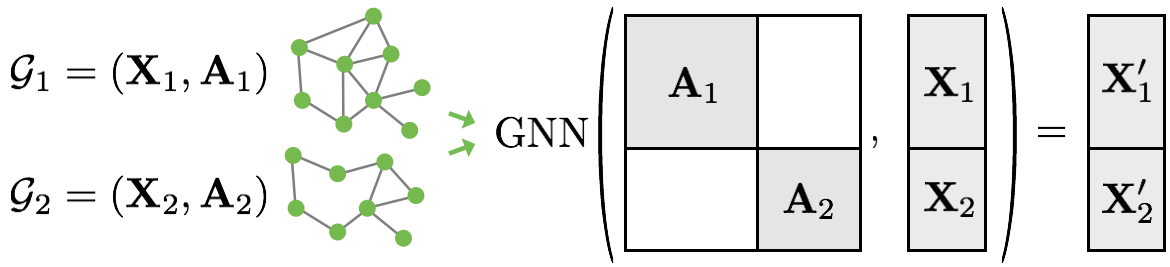
The adjacency matrix is zero for any nodes that come from two different graphs, and otherwise according to the adjacency matrix of the individual graph. Luckily, this strategy is already implemented in torch geometric, and hence we can use the corresponding data loader:
[22]:
graph_train_loader = geom_data.DataLoader(train_dataset, batch_size=64, shuffle=True)
graph_val_loader = geom_data.DataLoader(test_dataset, batch_size=64) # Additional loader if you want to change to a larger dataset
graph_test_loader = geom_data.DataLoader(test_dataset, batch_size=64)
Let’s load a batch below to see the batching in action:
[23]:
batch = next(iter(graph_test_loader))
print("Batch:", batch)
print("Labels:", batch.y[:10])
print("Batch indices:", batch.batch[:40])
Batch: Batch(batch=[687], edge_attr=[1512, 4], edge_index=[2, 1512], x=[687, 7], y=[38])
Labels: tensor([1, 1, 1, 0, 0, 0, 1, 1, 1, 0])
Batch indices: tensor([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2])
We have 38 graphs stacked together for the test dataset. The batch indices, stored in batch, show that the first 12 nodes belong to the first graph, the next 22 to the second graph, and so on. These indices are important for performing the final prediction. To perform a prediction over a whole graph, we usually perform a pooling operation over all nodes after running the GNN model. In this case, we will use the average pooling. Hence, we need to know which nodes should be included in which
average pool. Using this pooling, we can already create our graph network below. Specifically, we re-use our class GNNModel from before, and simply add an average pool and single linear layer for the graph prediction task.
[24]:
class GraphGNNModel(nn.Module):
def __init__(self, c_in, c_hidden, c_out, dp_rate_linear=0.5, **kwargs):
"""
Inputs:
c_in - Dimension of input features
c_hidden - Dimension of hidden features
c_out - Dimension of output features (usually number of classes)
dp_rate_linear - Dropout rate before the linear layer (usually much higher than inside the GNN)
kwargs - Additional arguments for the GNNModel object
"""
super().__init__()
self.GNN = GNNModel(c_in=c_in,
c_hidden=c_hidden,
c_out=c_hidden, # Not our prediction output yet!
**kwargs)
self.head = nn.Sequential(
nn.Dropout(dp_rate_linear),
nn.Linear(c_hidden, c_out)
)
def forward(self, x, edge_index, batch_idx):
"""
Inputs:
x - Input features per node
edge_index - List of vertex index pairs representing the edges in the graph (PyTorch geometric notation)
batch_idx - Index of batch element for each node
"""
x = self.GNN(x, edge_index)
x = geom_nn.global_mean_pool(x, batch_idx) # Average pooling
x = self.head(x)
return x
Finally, we can create a PyTorch Lightning module to handle the training. It is similar to the modules we have seen before and does nothing surprising in terms of training. As we have a binary classification task, we use the Binary Cross Entropy loss.
[25]:
class GraphLevelGNN(pl.LightningModule):
def __init__(self, **model_kwargs):
super().__init__()
# Saving hyperparameters
self.save_hyperparameters()
self.model = GraphGNNModel(**model_kwargs)
self.loss_module = nn.BCEWithLogitsLoss() if self.hparams.c_out == 1 else nn.CrossEntropyLoss()
def forward(self, data, mode="train"):
x, edge_index, batch_idx = data.x, data.edge_index, data.batch
x = self.model(x, edge_index, batch_idx)
x = x.squeeze(dim=-1)
if self.hparams.c_out == 1:
preds = (x > 0).float()
data.y = data.y.float()
else:
preds = x.argmax(dim=-1)
loss = self.loss_module(x, data.y)
acc = (preds == data.y).sum().float() / preds.shape[0]
return loss, acc
def configure_optimizers(self):
optimizer = optim.AdamW(self.parameters(), lr=1e-2, weight_decay=0.0) # High lr because of small dataset and small model
return optimizer
def training_step(self, batch, batch_idx):
loss, acc = self.forward(batch, mode="train")
self.log('train_loss', loss)
self.log('train_acc', acc)
return loss
def validation_step(self, batch, batch_idx):
_, acc = self.forward(batch, mode="val")
self.log('val_acc', acc)
def test_step(self, batch, batch_idx):
_, acc = self.forward(batch, mode="test")
self.log('test_acc', acc)
Below we train the model on our dataset. It resembles the typical training functions we have seen so far.
[26]:
def train_graph_classifier(model_name, **model_kwargs):
pl.seed_everything(42)
# Create a PyTorch Lightning trainer with the generation callback
root_dir = os.path.join(CHECKPOINT_PATH, "GraphLevel" + model_name)
os.makedirs(root_dir, exist_ok=True)
trainer = pl.Trainer(default_root_dir=root_dir,
callbacks=[ModelCheckpoint(save_weights_only=True, mode="max", monitor="val_acc")],
accelerator="gpu" if str(device).startswith("cuda") else "cpu",
devices=1,
max_epochs=500,
enable_progress_bar=False)
trainer.logger._default_hp_metric = None # Optional logging argument that we don't need
# Check whether pretrained model exists. If yes, load it and skip training
pretrained_filename = os.path.join(CHECKPOINT_PATH, f"GraphLevel{model_name}.ckpt")
if os.path.isfile(pretrained_filename):
print("Found pretrained model, loading...")
model = GraphLevelGNN.load_from_checkpoint(pretrained_filename)
else:
pl.seed_everything(42)
model = GraphLevelGNN(c_in=tu_dataset.num_node_features,
c_out=1 if tu_dataset.num_classes==2 else tu_dataset.num_classes,
**model_kwargs)
trainer.fit(model, graph_train_loader, graph_val_loader)
model = GraphLevelGNN.load_from_checkpoint(trainer.checkpoint_callback.best_model_path)
# Test best model on validation and test set
train_result = trainer.test(model, graph_train_loader, verbose=False)
test_result = trainer.test(model, graph_test_loader, verbose=False)
result = {"test": test_result[0]['test_acc'], "train": train_result[0]['test_acc']}
return model, result
Finally, let’s perform the training and testing. Feel free to experiment with different GNN layers, hyperparameters, etc.
[27]:
model, result = train_graph_classifier(model_name="GraphConv",
c_hidden=256,
layer_name="GraphConv",
num_layers=3,
dp_rate_linear=0.5,
dp_rate=0.0)
GPU available: True, used: True
I1113 19:12:54.045717 139969460983616 distributed.py:49] GPU available: True, used: True
TPU available: False, using: 0 TPU cores
I1113 19:12:54.047091 139969460983616 distributed.py:49] TPU available: False, using: 0 TPU cores
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
I1113 19:12:54.048336 139969460983616 accelerator_connector.py:385] LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
/home/phillip/anaconda3/envs/nlp1/lib/python3.7/site-packages/pytorch_lightning/utilities/distributed.py:45: UserWarning: Your test_dataloader has `shuffle=True`, it is best practice to turn this off for validation and test dataloaders.
warnings.warn(*args, **kwargs)
Found pretrained model, loading...
[28]:
print(f"Train performance: {100.0*result['train']:4.2f}%")
print(f"Test performance: {100.0*result['test']:4.2f}%")
Train performance: 94.27%
Test performance: 92.11%
The test performance shows that we obtain quite good scores on an unseen part of the dataset. It should be noted that as we have been using the test set for validation as well, we might have overfitted slightly to this set. Nevertheless, the experiment shows us that GNNs can be indeed powerful to predict the properties of graphs and/or molecules.
Conclusion
In this tutorial, we have seen the application of neural networks to graph structures. We looked at how a graph can be represented (adjacency matrix or edge list), and discussed the implementation of common graph layers: GCN and GAT. The implementations showed the practical side of the layers, which is often easier than the theory. Finally, we experimented with different tasks, on node-, edge- and graph-level. Overall, we have seen that including graph information in the predictions can be crucial for achieving high performance. There are a lot of applications that benefit from GNNs, and the importance of these networks will likely increase over the next years.
 If you found this tutorial helpful, consider ⭐-ing our repository.
If you found this tutorial helpful, consider ⭐-ing our repository. For any questions, typos, or bugs that you found, please raise an issue on GitHub.
For any questions, typos, or bugs that you found, please raise an issue on GitHub.